-
26年磨一劍!全台首個主顧品牌作業系統正式發表… AI 讓品牌、行銷更簡單,他打造「六脈18掌」方法論 !
今週刊 :
https://www.businesstoday.com.tw/article/category/183015/post/202604170039/
26年磨一劍!全台首個主顧品牌作業系統正式發表… AI 讓品牌、行銷更簡單,他打造「六脈18掌」方法論 ! 📮今週刊 : https://www.businesstoday.com.tw/article/category/183015/post/202604170039/ 0 Comments ·0 Shares ·147 Views .0 Reviews.33
0 Comments ·0 Shares ·147 Views .0 Reviews.33
-
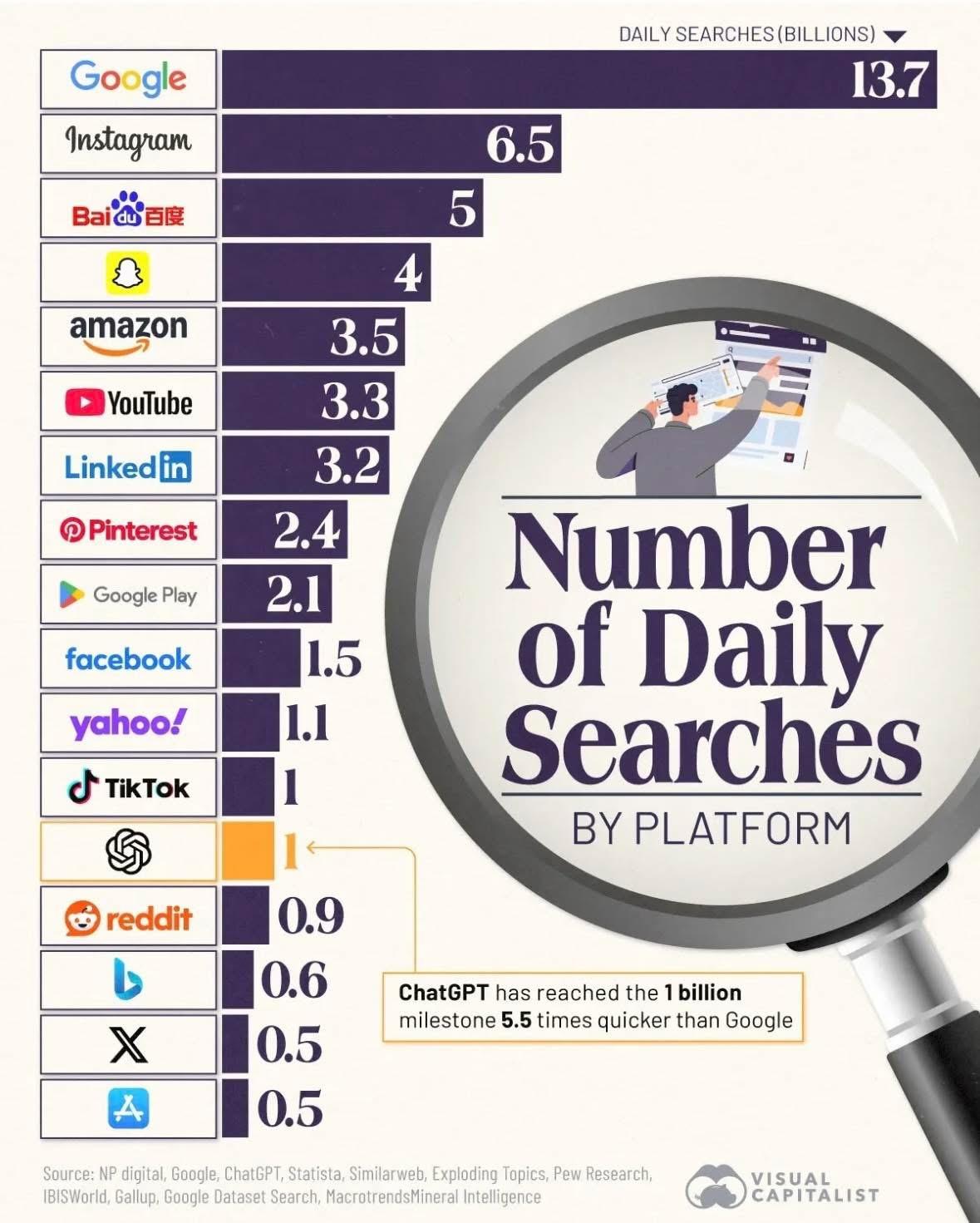
新聞監測服務透過 AI 與大數據技術,24小時全天候追蹤新聞、社群
(FB/Dcard/PTT)及論壇資訊,主動預警負面輿情、追蹤競爭對手與分析品牌聲量。主流平台如 QuickseeK、OpView、Wisers 和 KEYPO 提供客製化關鍵字監測與即時數據分析,協助企業制定營銷策略與危機處理。
TPOC台灣議題研究中心
TPOC台灣議題研究中心
主流新聞與輿情監測平台
QuickseeK 快析輿情資料庫:專注即時通報,每半小時更新,適合突發危機預警。
OpView 社群口碑資料庫:國內最全面的社群媒體分析平台,適用於深度的輿情分析與社群口碑調查。
Wisers 慧科訊業:提供一站式媒體大數據服務,擅長長期的趨勢分析與AI數據洞察。
KEYPO 大數據關鍵引擎:擅長利用AI進行精準語意與情緒分析,適合高階聲量監測。
QSearch:擅長社群數據分析,適用於追蹤臉書粉專等網路熱議話題。
MGBOX台灣議題研究中心
新聞監測服務的核心功能
實時監測與預警:自動化掃描超過10萬個公開頻道,重要輿情即時透過LINE或郵件通知。
情感與語意分析:AI技術自動判讀新聞與網友評論是正面、負面或中性,快速判斷聲量意涵。
競爭對手分析:監測競品的市場活動、報導數量與市場反應。
自動化分析報告:產出每日、每週數據趨勢報告,幫助理解公眾意見的變化。
TPOC台灣議題研究中心
TPOC台灣議題研究中心
+5
適用場景
品牌公關與危機處理:及時掌握負面新聞,在危機爆發前採取行動。
行銷策略制定:洞察消費者趨勢、熱門關鍵字,優化行銷素材。
政府與人物宣傳:掌握公共議題動向,精準引導民意。
Wisers
Wisers
+2
建議根據企業的預算、監測的複雜度以及對即時性的要求,選擇合適的系統。📮新聞監測服務透過 AI 與大數據技術,24小時全天候追蹤新聞、社群 (FB/Dcard/PTT)及論壇資訊,主動預警負面輿情、追蹤競爭對手與分析品牌聲量。主流平台如 QuickseeK、OpView、Wisers 和 KEYPO 提供客製化關鍵字監測與即時數據分析,協助企業制定營銷策略與危機處理。 TPOC台灣議題研究中心 TPOC台灣議題研究中心 📮主流新聞與輿情監測平台 QuickseeK 快析輿情資料庫:專注即時通報,每半小時更新,適合突發危機預警。 OpView 社群口碑資料庫:國內最全面的社群媒體分析平台,適用於深度的輿情分析與社群口碑調查。 Wisers 慧科訊業:提供一站式媒體大數據服務,擅長長期的趨勢分析與AI數據洞察。 KEYPO 大數據關鍵引擎:擅長利用AI進行精準語意與情緒分析,適合高階聲量監測。 QSearch:擅長社群數據分析,適用於追蹤臉書粉專等網路熱議話題。 MGBOX台灣議題研究中心 新聞監測服務的核心功能 實時監測與預警:自動化掃描超過10萬個公開頻道,重要輿情即時透過LINE或郵件通知。 情感與語意分析:AI技術自動判讀新聞與網友評論是正面、負面或中性,快速判斷聲量意涵。 競爭對手分析:監測競品的市場活動、報導數量與市場反應。 自動化分析報告:產出每日、每週數據趨勢報告,幫助理解公眾意見的變化。 TPOC台灣議題研究中心 TPOC台灣議題研究中心 +5 適用場景 品牌公關與危機處理:及時掌握負面新聞,在危機爆發前採取行動。 行銷策略制定:洞察消費者趨勢、熱門關鍵字,優化行銷素材。 政府與人物宣傳:掌握公共議題動向,精準引導民意。 Wisers Wisers +2 建議根據企業的預算、監測的複雜度以及對即時性的要求,選擇合適的系統。 0 Comments ·0 Shares ·81 Views .0 Reviews.22
0 Comments ·0 Shares ·81 Views .0 Reviews.22
-
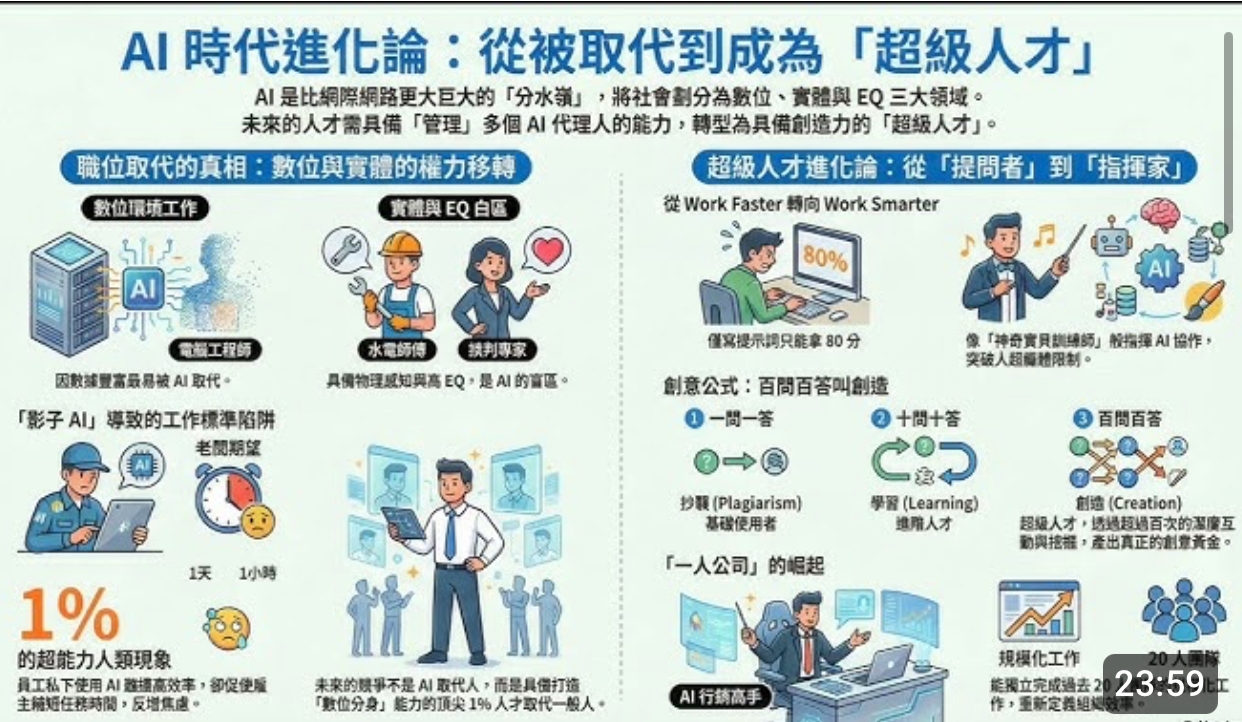
博士專家告訴您最新的🆕AI 運用邏輯 ! https://youtu.be/2C2DdwPQ4q8
 0 Comments ·0 Shares ·429 Views .0 Reviews.66
0 Comments ·0 Shares ·429 Views .0 Reviews.66
-
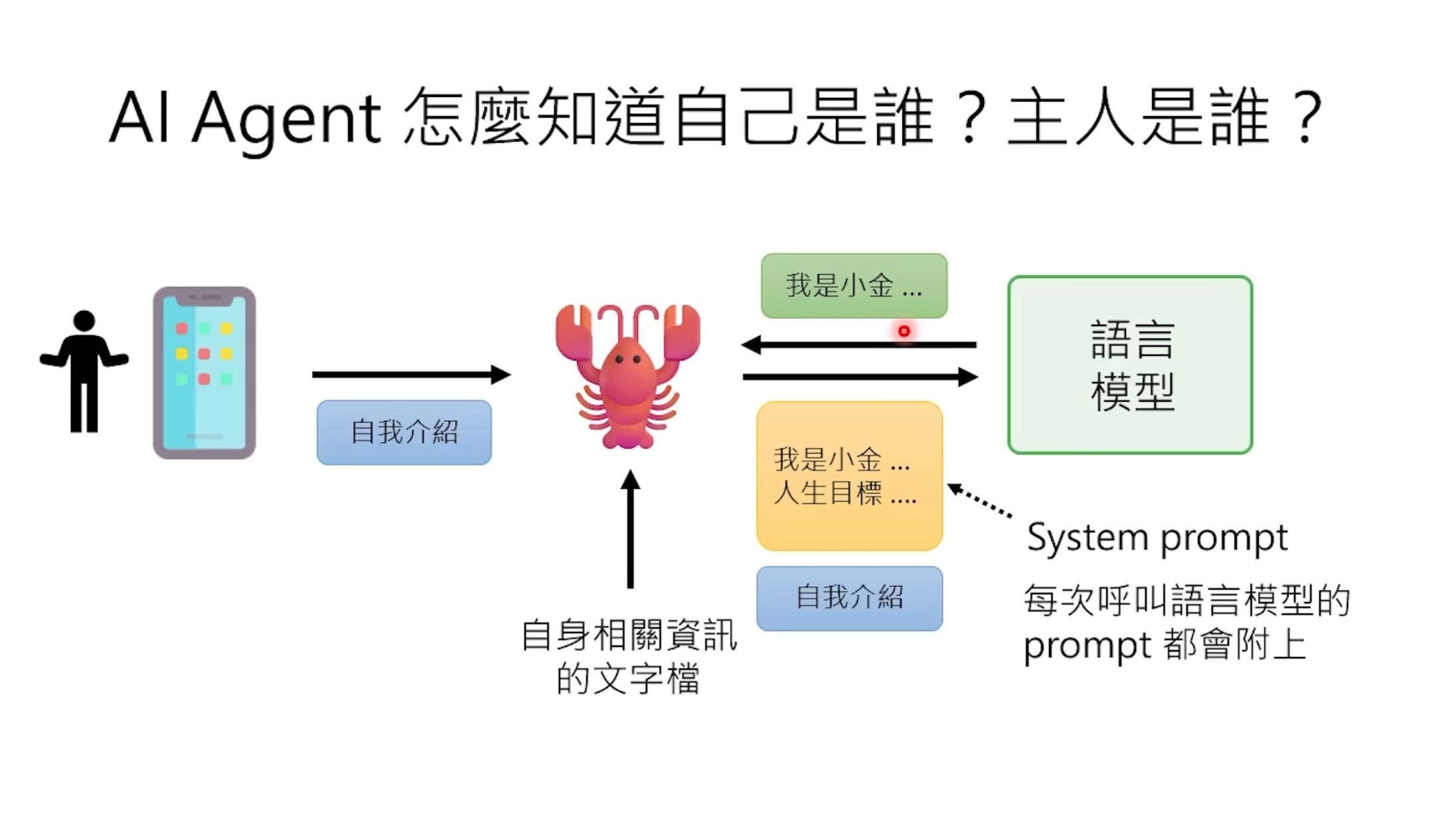
龍蝦🦞的工作流程 : https://youtu.be/2rcJdFuNbZQ?si=j7WbkG44_PyWtlJn
 0 Comments ·0 Shares ·373 Views .0 Reviews.33
0 Comments ·0 Shares ·373 Views .0 Reviews.33
-
全球如何搶著養龍蝦🦞! https://youtu.be/2rcJdFuNbZQ?si=jDvJPpY3nVSP33hB #龍蝦 #養龍蝦 #OpenClaw
 0 Comments ·0 Shares ·467 Views .0 Reviews.33
0 Comments ·0 Shares ·467 Views .0 Reviews.33
More Stories
